
EPRI uses Dell Pro Max with NVIDIA GB10 to run custom AI workflows locally to help protect sensitive data, accelerating research without compromise.
Artificial intelligence is quickly becoming a critical tool for organizations working at the intersection of infrastructure, safety and public trust. In the energy sector and at research institutions like EPRI, AI adoption poses unique challenges. Data sensitivity, regulatory requirements and the need for deep domain reasoning make cloud‑only approaches difficult to scale responsibly.
To move faster without compromising security or control, EPRI is exploring new ways to bring advanced AI closer to the data. With the Dell Pro Max with GB10 equipped with the NVIDIA Grace Blackwell Superchip, EPRI can develop, test and run custom AI workflows locally — unlocking new levels of insight while keeping sensitive information firmly on premises.

Pain points: AI at scale, without losing control
EPRI collaborates with the global energy industry with research, development and demonstrations that directly impact grid reliability, safety and long‑term resilience. That work increasingly depends on AI models capable of reasoning across dense, technical documents and complex datasets.

But traditional AI infrastructure models introduce friction:
- Cloud dependence creates cost uncertainty, especially for iterative model development and experimentation.
- Data movement is often restricted, as operational and research data may not be permitted to leave controlled environments.
- Security and governance requirements demand strict isolation, auditability and compliance.
- Latency and bandwidth constraints can slow down interactive AI workflows when models are hosted remotely.
The challenge isn’t whether to use AI, it’s how to deploy it in a way that aligns with the realities of the energy industry and other highly regulated domains.
A new value proposition: Local AI, built for real‑world constraints
Dell Pro Max with GB10, accelerated by the NVIDIA Grace Blackwell Superchip introduces a fundamentally different approach to AI infrastructure.
With the GB10, teams can:
- Run large AI models locally, supporting up to 200B parameters on a single system, or 400B parameters by stacking two units with ultra‑low‑latency interconnect.
- 128 GB of unified system memory to keep large models and datasets in‑memory for responsive local fine‑tuning and inference.
- Harnesses the power of Grace Blackwell architecture delivering 1 petaFLOP of AI performance for fine-tuning, inference and analytics.
- Shift AI investment from unpredictable cloud consumption to a predictable, owned performance model.
- Maintain flexibility to scale workloads to the data center or cloud when appropriate, without rearchitecting.
This model supports advanced AI research while preserving the control and transparency required in energy‑sector environments.
Enabling On‑Prem AI with Dell Pro Max and NVIDIA Acceleration
Dell Pro Max with GB10 is engineered for organizations that treat data privacy and operational integrity as non‑negotiable. By running AI workloads entirely on premises, teams maintain full control over sensitive research data and avoid the exposure risks associated with external networks. This approach supports the stringent governance and regulatory expectations that define energy‑sector operations, while also enabling deployment in air‑gapped or edge environments where connectivity must be limited or tightly controlled.
Powered by NVIDIA DGX OS, the GB10 system delivers a stable and fully integrated NVIDIA AI software stack, enabling researchers to develop AI tools locally using the same environment they would rely on in larger enterprise infrastructures. With the Grace Blackwell Superchip, acceleration becomes a catalyst for real productivity. Delivering rapid inference, fluid model execution and smooth interaction with large, reasoning‑intensive datasets. This level of performance doesn’t just make AI faster; it makes it more dependable. These capabilities create a high‑performance foundation that empowers organizations to drive AI innovation forward while maintaining uncompromising control, complete visibility and the compliance posture their work demands.
From research to real‑time insight: How EPRI built power chat
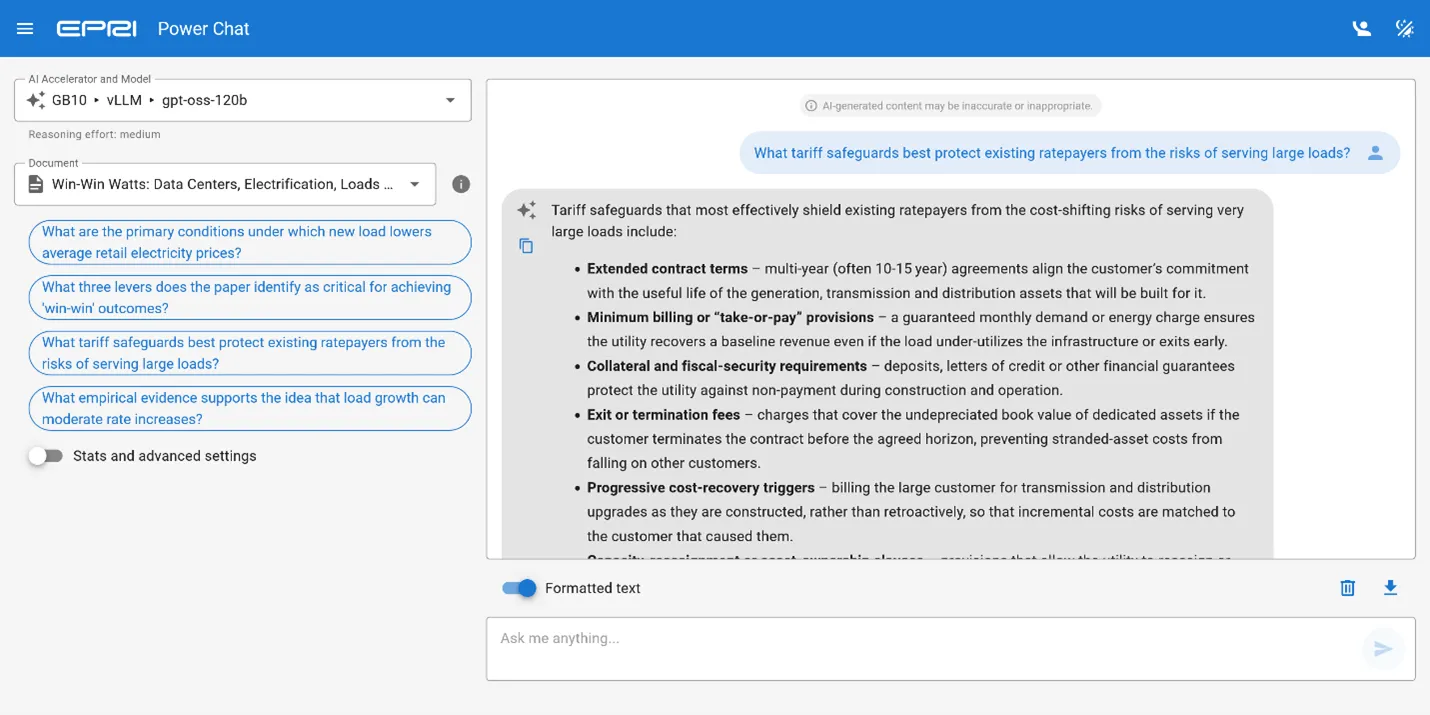
In early 2026, EPRI developed Power Chat, a prototype demonstrating how document-grounded AI assistant can run entirely on a compact supercomputer—the Dell Pro Max with GB10. Power Chat enables deep, conversational exploration of technical documents through a streamline interface and a fully local workflow designed for controlled environments.
Users begin by selecting documents that are loaded into the model’s memory, enabling cache-augmented generation for near-instant recall across sessions. This allows users to ask anything from precise questions about specific content to broader inquiries about the implications of a technical topic. The goal is a faster path to insight from large, dense documents, improving access to critical information and supporting decision-making.
Power Chat uses gpt-oss-120b, an open-weight mixture-of-experts LLM that activates 5.1 billion parameters per token and uses an ultra-compact 4-bit MXFP4 data format. This combination keeps inference efficient while maintaining the depth and quality expected from a 120B-class model.
This model is served through vLLM, an open-source inference engine optimized for high throughput and memory efficiency. One of vLLM’s capabilities is prefix caching, which enables the system to encode documents once and store the encoded representations in memory (KV cache). Power Chat leverages this by allocating an expanded memory region for the KV cache, ensuring fast recall across sessions without re-encoding.
At the hardware level, the Dell Pro Max with GB10 features the cutting-edge NVIDIA Grace Blackwell architecture. With 128GB of unified memory, it streamlines data sharing between CPU and GPU, which is essential to enabling Power Chat’s architecture. It offers enough capacity to load gpt-oss-120b in MXFP4 format (68 GiB), maintain a 1-million-token KV cache in FP8 format (36 GiB) and have sufficient memory remaining for the operating system and supporting processes.
The system takes about 15 minutes to boot, load the model and encode documents into the KV cache. Once warmed, responses begin streaming within seconds. EPRI measured 35 tokens per second for single-user requests. With multiple users, throughput is shared; for example, at 10 concurrent requests, EPRI observed 15 tokens per second for a total of 150 tokens per second.
The GB10 enables EPRI to demonstrate a fully self-hosted document chat assistant that would traditionally require larger and more expensive GPU servers. Its compact footprint supports concurrent use by small teams, illustrating how modest on-prem systems can lower the barrier to developing and operating customer AI-accelerated workflows while appropriately managing sensitive information and supporting alignment with existing data protection policies.
Why this matters beyond energy
While EPRI is a nonprofit organization whose mission is rooted in energy research to benefit society, its impact reaches far beyond that. Other industries face many of the same realities: highly sensitive data, rigorous compliance demands and the need for AI systems that are both explainable and trustworthy. Dell Pro Max with GB10 demonstrates how advanced AI can operate securely, locally and at deskside scale, setting a clear path for organizations that require data sovereignty and high‑performance computing to coexist.
Build AI where it matters most
With Dell Pro Max with GB10, organizations can take ownership of their AI performance, protect their data and accelerate innovation on their own terms.
Ready to meet the future of AI development at the deskside?
Explore how Dell Pro Max with GB10 powered by NVIDIA Grace Blackwell architecture and NVIDIA DGX OS can help your teams build, test and deploy advanced AI, click here to learn more.
Interested in running AI workloads on your Dell Pro Max with GB10? Get started here, with NVIDIA’s playbooks.






